")
Fala maker tudo bem com vocês? Hoje vamos dar continuidade a nossa série sobre Arduino e Python! Clique aqui para ver o nosso primeiro tutorial da série! Neste parte 2 vamos aprender sobre assistente virtual! Um assistente virtual é um robô que pode estar instalado em seu computador, em uma caixa de som, no seu carro ou embarcado em uma placa como o Raspberry, ele tem a função de auxiliar em atividades como ligar eletrodomésticos, lembretes, leitura de livros e pesquisas na internet por exemplo. Alguns modelos comerciais temos a Siri, Cortana e o Jarvis, neste e-book iremos fazer um conceito e programar um assistente com comandos simples e sem inteligência Artificial.
A Cortana, por exemplo, é a assistente virtual da Microsoft. Ou seja, suas funções são parecidas com as da Siri, da Apple, ou do Google Assistente, do Google, ela possui uma inteligência artificial aprendendo com os hábitos de utilização do usuário. Dessa forma, quanto mais você usa a assistente virtual, mais personalizadas ficam as respostas. Sem esquecer, claro, da possibilidade de usar comandos de voz em algumas ações.
Uma das vantagens da Cortana é que a assistente virtual pode ser usada em computadores e notebooks com Windows 10 e em smartphones Android e iOS, por meio do aplicativo. Dessa forma, todas as suas informações podem ser acessadas em diferentes dispositivos.

Preparando o projeto
Para iniciar o nosso primeiro projeto de nossa série sobre Python e Arduino, que será um assistente virtual, precisaremos instalar algumas dependências. E vamos aprender e revisar o básico do Python, vamos instalar as bibliotecas necessárias para esta primeira parte do projeto, são elas:
- pyttsx3 – Text-to-speech TTS ( https://pypi.org/project/pyttsx3/ )
Biblioteca Text to Speech (TTS) para Python 2 e 3. Funciona sem conexão à internet ou atraso. Suporta vários motores TTS, incluindo Sapi5, nsss e espeak.
- pyaudio – Python Bindings for PortAudio ( https://pypi.org/project/PyAudio/ )
Vinculações para PortAudio v19, a biblioteca para gerenciamento de entrada e saída de áudio entre plataformas.
- speech recognition ( https://pypi.org/project/SpeechRecognition/ )
Biblioteca para realização de reconhecimento de fala, com suporte para vários motores e APIs, on-line e off-line.
Para instalar essas bibliotecas, escreva CMD na barra de pesquisa do Windows:
Depois clique no aplicativo Prompt de Comando:
Irá surgir uma caixa preta chamada Prompt de Comando:
E digite as instruções abaixo em seu diretório CMD:

Caso seu Windows não permita a instalação do Pyaudio, siga os passos seguintes substituindo o _pip install pyaudio_ anterior:

Quer aprender mais sobre Python e Arduino, confira o nosso curso no Youtube:
Mergulhando no código
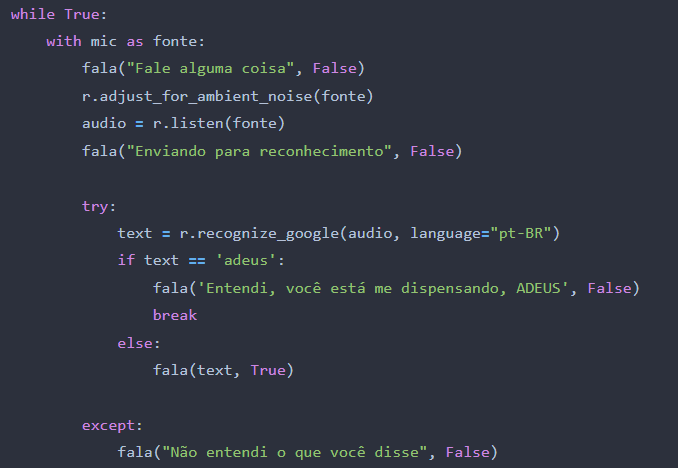
Segue o código completo do primeiro projeto da nossa série sobre Python e Arduino, o nosso assistente virtual:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 20 18:29:09 2021
@author: sandr
"""
import pyttsx3
engine = pyttsx3.init()
import speech_recognition as sr
r = sr.Recognizer()
mic = sr.Microphone()
def fala(text, tipo):
if tipo:
print("Você disse: {}".format(text))
engine.say("Você disse: {}".format(text))
else:
print(text)
engine.say(text)
engine.runAndWait()
engine.stop()
while True:
with mic as fonte:
fala("Fale alguma coisa", False)
r.adjust_for_ambient_noise(fonte)
audio = r.listen(fonte)
fala("Enviando para reconhecimento", False)
try:
text = r.recognize_google(audio, language="pt-BR")
if text == 'adeus':
fala('Entendi, você está me dispensando, ADEUS', False)
break
else:
fala(text, True)
except:
fala("Não entendi o que você disse", False)
A primeira coisa será importar o pacote PYTTSX3:

O pacote PYTTSX3 é uma biblioteca OFFLINE de texto em fala Python (TTS) que funciona tanto para python3 quanto para python2. Esta biblioteca é muito útil, especialmente se você não deseja nenhum atraso no discurso produzido e não deseja depender apenas da Internet para a conversão de TTS. Ele também suporta vários mecanismos TTS como Sapi5, nsss, espeak.
Podemos baixá-la e instalar usando o comando: pip install pyttsx3 no CMD de seu computador, o link ao lado explica um pouco mais sobre o pacote e como baixá-lo.
E o que é esse TTS? TTS, que significa Text to Speech, nada mais é do que uma técnica de sintetização da fala humana, que converte texto em linguagem normal. Ou seja, uma pesquisa sobre um conceito de tecnologia num evento de tecnologia. Muitos usam esse pacote, mas poucos entendem o que realmente significa TTS, agora nós sabemos.
Para instalar em outro sistema operacional eu recomendo a leitura no site: https://pyttsx.readthedocs.io/en/latest/install.html
Continuando o desmembramento de nosso código, na linha 7, o meu programa chama a função .init( ) do meu pacote pyttsx, pyttsx.init( ), para inicializar e obter uma referência para o meu pacote de texto que suporta até 2 vozes, uma do sexo feminino e outra do sexo masculino fornecido pelo SAPI5 no caso do Windows, no MAC OSx o mecanismo TTS é o nsss – NSSpeechSynthesizer e para qualquer outro sistema operacional o mecanismo usado será o speak – Speak . Ainda na mesma linha eu crio um objeto chamado engine.
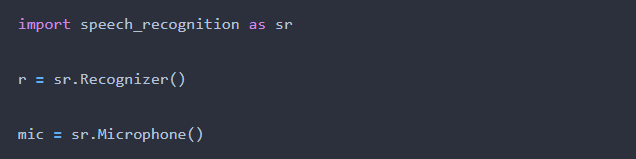
Importamos o pacote de reconhecimento de fala ( _speech_recognition_ ) e como ele é um nome grande, quando formos usá-lo como objeto ficaria um pouco trabalhoso ficar reescrevendo o nome “speech_recognition”, logo abreviamos esse nome para “sr”, assim fica mais fácil e prático a escrita do código.
O método _Recognizer_ ativa a função de reconhecimento de fala e áudio e pega as configurações de seu computador para usá-la no reconhecimento. Observe que usamos o objeto “sr” para chamar o método e as informações adquiridas já atribuímos a um novo objeto que chamamos de “r”.
O método _Microphone_ também chamado pelo objeto “sr” tem a função de habilitar o microfone para ouvir o usuário do Assistente Virtual e já atribuímos a um novo objeto que chamamos de “mic”.
Agora, logo abaixo, criamos uma função que irá realizar a tarefa do *__Python Falar__*.
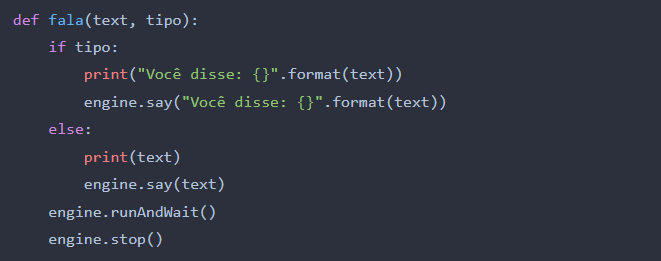
Criamos uma nova função chamada __fala( )__ onde ela aguardará 02 informações, o texto que irá reproduzir em audio e no segundo parâmetro um dado booleano True ou False que define se irá falar uma frase pré definida ou se algo que ouviu, isso é decidido na linha seguinte na condicional ___if__ tipo:_ caso parâmetro recebido seja _True_ e logo irá reproduzir a frase recebida com a varável _text_ ou, na segunda condição, ___else:___ caso o parâmetro passado seja _False_ irá reproduzir um texto pré-definido.
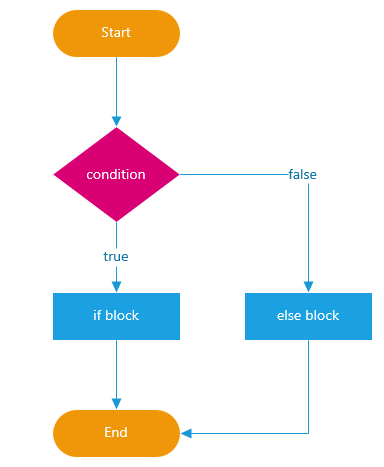
Condicional IF/ELSE
A condicional IF/ELSE é um teste onde SE a condição for verdadeira execute uma tarefa SENÃO executa outra tarefa:
Segue abaixo um exemplo explicativo sobre IF/ELSE que não faz parte do nosso projeto:
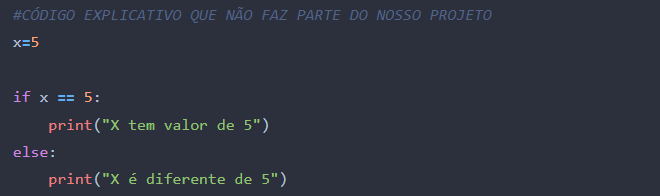
Você observou que usamos o “==”? Esse símbolo ai é chamado de operador condicional, os Operadores Condicionais são utilizados para fazer as comparações dos valores que são passados e retornam o valor Verdadeiro ou Falso.
Abaixo temos um tabela com os operadores do Python:
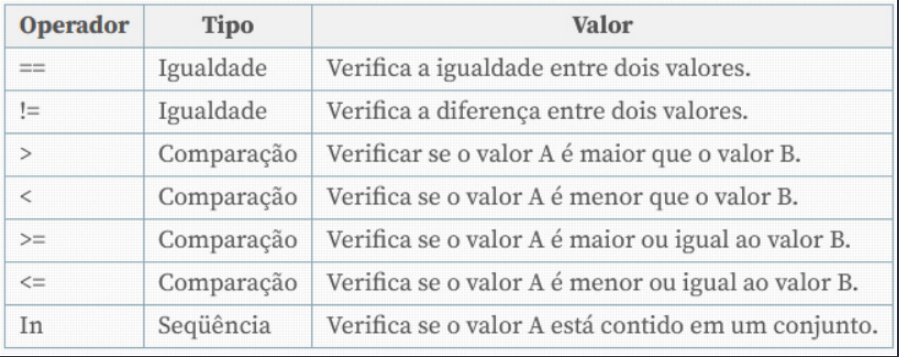
Como você pode ver, não existe apenas o operador de igualdade, tantos outros ainda devem ser estudados, te desafio a fazer uma pesquisa na documentação do Python para se aprofundar um pouco mais.
De volta ao código do projeto
O comando engine.say(texto) ordena que o Python diga (say em inglês) o que está carregado na variável texto através do objeto engine que foi criado anteriormente e carrega toda a configuração para executar essa tarefa. Logo, tudo que ele ouvir estará na variável _texto_ entre parênteses e usando o método .say irá ser dito em voz pelo seu computador.
Na função .runAndWait( ) , o seu Python irá pronunciar o texto que foi carregado no objeto engine na linha anterior, esse método é importante pois sua função consiste em duas ações básicas, a ordem de executar a pronúncia do texto e aguardar um tempo para garantir a execução completa.
O comando de parar o processo de reprodução da fala é executado através do engine.stop( ), deixando assim o programa livre para as próximas ações necessárias.
A saída esperada será uma conversação de texto e áudio com você:

Na primeira linha após o While True: criamos um _with mic as fonte:_ para ouvir o microfone então já com o “mic em mãos”, dizemos para o Python praticamente assim com essa linha de comando: “Python use a sua configuração do microfone com a fonte, que seria sua voz captada”.
Logo na linha seguinte é chamada a função fala( ), criada no bloco anterior, onde nela passamos 02 parâmetros, o texto que irá falar e se é True ou False esse True e False é referente a se o assistente ouviu ou não alguma coisa.
Iniciamos a função de redução de ruído através do objeto “r” usando o comando r.adjust_for_ambient_noise(fonte) que trata do reconhecimento de fala disponível no pacote “speech_recognition” e aplico essa redução de ruído passando como parâmetro a minha “fonte”.
A função “listen” coloca o reconhecimento em modo passivo e armazena a informação que ouviu na variável áudio.
O try: é a chave de entrada para passar o áudio para o Google Reconize, e a função de redução de ruído através do objeto “r” usando o comando r.adjust_for_ambient_noise(fonte) que trata do reconhecimento de ogle ou informar para o usuário que meu assistente não entendeu o que foi dito, logo o “try” é um teste onde se o programa estiver reconhecido um padrão de fala permitirá entrar nessa condicional e dar continuidade a conversa, caso contrário o programa pula para a próxima linha habilitando o acesso a função do Google.
Agora chegou a hora de confirmar o que meu Assistente virtual ouviu, pois a informação salva na variável “text” da linha anterior será impressa nessa linha usando o método “.format()”. O método format() serve para criar uma string que contém campos entre chaves a serem substituídos pelos argumentos de format. Repare os campos de substituição na string (que é tudo que está entre aspas) estão associadas aos parâmetros de format onde se eu tivesse dentro da string 3 chaves o meu format passaria 3 parâmetros que respectivamente cada parâmetro corresponderia a uma chave.
Se o nosso assistente ouvir a palavra adeus ele irá encerrar o programa.

Conclusão
Hoje fizemos o nosso primeiro projeto em Python da nossa série sobre Python e Arduino! E vimos com a linguagem é de fácil aprendizagem e ao mesmo tempo é extremamente robusta. Com um código bem sucinto conseguimos desenvolver um assiste virtual de voz! Em nosso próximo post dessa série iremos aprender como integrar Arduino com o Python!
Deixe uma resposta